A.1 Hardware dependency of attacksPermalink
We found that the iterative methods ILLM and BIM can produce significantly different adversaries and adversarial confidences on different hardware. For example, sample 162 achieves a confidence of about 42% on a MacBook but 69% when calculated on Colab. These confidences as well as adversaries are consistent on the same hardware. We also isolated this phenomenon to the generation of the adversaries. Predictions with clean images yield the same results on different hardware (besides the usual floating point processing related differences).
To analyze this behaviour we have conducted the following experiment. In a first part we have generated 20 adversaries for multiple samples, chosen at random. On both machines the results were exactly the same respectively.
In the second part we modify the attack_ILLM function so that it saves the sum of all absolute pixel values for the adversaries in each iteration as well as the sum over all dimensions of the absolute gradients. In figure A.1 you can see how they differ after the first iteration.
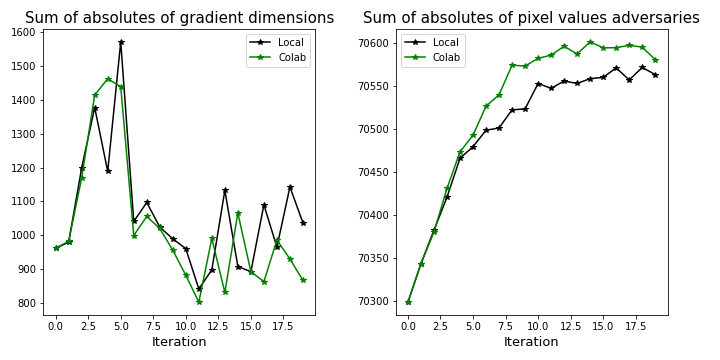
With each iteration the difference of the gradient becomes larger and with it the adversaries more different from one another. The number of pixels in an image seem to make this noticeable in the confidences. We see this as further proof for the brittleness of the predictions.